

In my previous post I talked about three differences between in-house and AWS deployments and specifically how it affects your architectural choices. Today I’ll talk about two more.
 Caching
Caching
This whitepaper by AWS illustrates their design philosophy and is well worth a read – especially from page 11. The two concepts of loosely coupling and massive parallelisation strike at a core difference between traditional and cloud computing architectures.
If you’ve worked with large traditional applications you’ll be aware that it is common for the database and storage tiers to be a performance bottleneck. Databases like Oracle are monolithic beasts that are hard to scale without spending a lot of coin and difficult to replace once they’re in place.
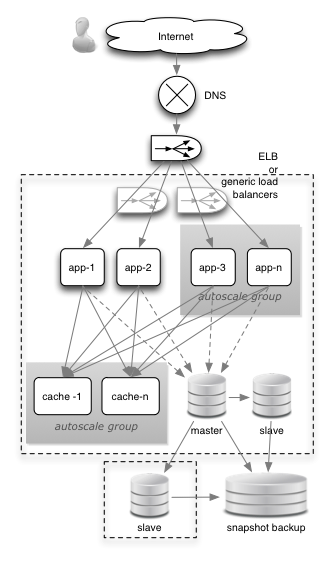
Whenever you see an AWS architecture there’s typically a database-boosting caching tier. Cloud workloads are typically more elastic and read-intensive (ie. web apps) so cloud architectures must handle bursty and read-hungry workloads.
The AWS caching product is ElastiCache, which comes in difference instance sizes just like EC2. ElastiCache is based on the open-source object cache memcached, or the NoSQL DB Redis (your choice).
The first time a database object is accessed it is read from the database and put in the cache. Every subsequent read is then directly from the cache until the time-to-live (TTL) on the object is reached or the cache restarted. Typically you set up multiple instances in difference availability zones for high availability. You must make sure that the TTL is set on database objects so that they get cycled regularly in the cache.
In the diagram above there is a separate caching tier. Another option is to install memcached on the application instances. In this case each cache instance is stand-alone and dedicated to its own application server.
Another increasingly popular alternative to caching is to use exclusively NoSQL databases. NoSQL databases provide eventual consistency but can’t do complex database operations very well. They are easy to develop with.
Security Groups
In an in-house architecture the network is divided up into a number of security zones that each have a trust rating: Low trust, high trust, untrusted etc. Zones instances (subnets, VLANs, or whatever) are then separated by firewalls (see below)
AWS replaces firewalling with the concept of security groups. I haven’t been able to find any information about how AWS actually implement security groups under the hood and that’s one problem with them. You have to blindly trust their implementation. Assuming AWS security groups will have vulnerabilities from time to time, you need extra protection. There’s also little in the way of auditing or logging and a lot of rules and constraints about security group usage too.
For business critical applications, where data and service protection are significant issues, extra security technologies to consider are: host-based firewalls (eg. iptables) and intrusion detection, web application firewall SaaS (eg. Imperva), data encryption technologies, using a Virtual Private Cloud, two factor authentication and vulnerability scanning amongst other things.
To get around this problem one pattern that emerges is that of keeping critical data and functions in a secure location, and sharing a common key with the application running in the cloud. For example, to be PCI-DSS compliant, many organisations hand off their credit card processing to a payment gateway provider so they never have to handle credit card data. The gateway passes back a token and transaction details to the application. The application never touches the sensitive data.
Security groups simplify your set-up though and are great for prototyping. You don’t need a network or security expert to get started. One of the reasons you went to the cloud was probably because you didn’t want to touch the network after all!
Summary
The differences I’ve chosen to focus on in this two-part blog are: load-balancing, storage, databases, caching and security groups/firewalls. The reasons I’ve chosen specifically these is because the implementation of, and philosophies behind, each drives a different overall design approach. To build your own hybrid clouds these differences will have to be reconciled.