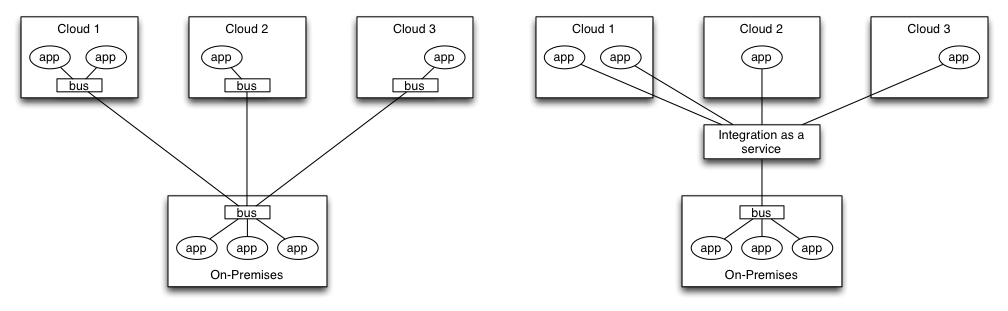
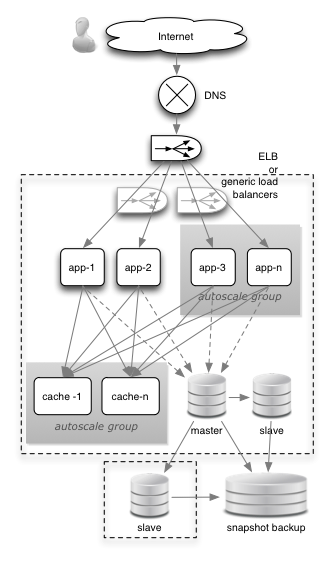
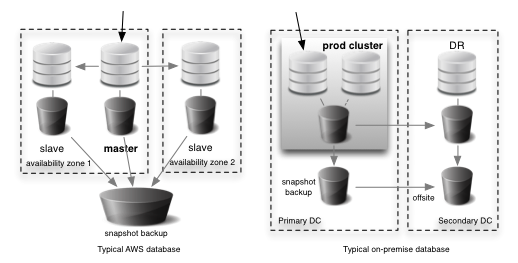
If you feel like a good read pick up a copy of Antifragile by Nassim Nicholas Taleb. Specifically read Chapter 3 temptingly titled “The Cat and The Washing Machine”.
A summary of the book in one line is: Antifragile things get better under stress. This is distinct from fragile things that break under stress, and robust things that persist.
Some antifragile examples used are:
- Human bodies that improve under certain levels of stress (eg. strength training) and;
- The airline system, which gets better with each single accident. Each accident improves the system (MH370 may prove to be an exception).
Chapter 3 argues that antifragile things tend to be organisms like “The Cat” whereas fragile things tend to be like the “The Washing Machine”.
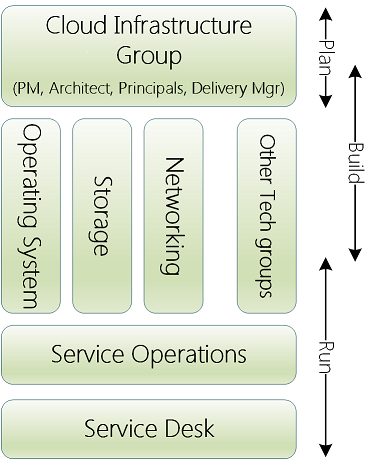
What does this have to do with IT Infrastructure? Historically we’ve aimed to build robust infrastructure. We’ve built environments with dual power supplies, backup data centres and RAID disk arrays. We build environments to be robust under stress. They don’t improve.
When IT hardware was expensive and scarce it may not have been justified to buy back-up hardware. You may have bought a single mainframe for one site, leaving your business exposed to a potential extended outage. That is, fragile.
Now in the days of IT abundance, IT infrastructure is vast and geographically dispersed. If one server dies in the cloud does anyone notice? Shadow IT, iPads, BYOD and opportunistic vendors make IT growth much more organic that it once was.
It isn’t urgent if a power supply or HDD dies anymore. What is tricky is understanding the complexity of key business functions and how they map to IT. Also, software is eating infrastructure. Physical assets can be robust, but never antifragile. Software is much more malleable and can improve.
As an aside I chatted to a lady at a cafe the other day. She was a nurse about to study LEAN. I was horrified. LEAN is all about minimising waste and maximising value, or in my mind, managerial efficiency pr0n. I imagine the LEAN consultants received less-than-lean money from the public health system. LEAN works well for manufacturing, but applying a model born out of Toyota to hospitals is MBA madness.
I have nothing against efficiency. I just don’t think LEAN works outside of manufacturing. In manufacturing you have slow-changing product life cycles, mass production and well understood customer needs.
Applying LEAN thinking to IT assumes IT is like “The Machine” where in fact it is becoming more like “The Cat”. In IT we don’t fully understand customer needs so we have tight iterations and close proximity to the end-user (ie. Agile). Product life cycles can be incredibly short. Look at mobile apps. Digital software products are not mass-produced. A single version is produced that copied/distributed one-by-one as needed. A large portion of IT work is not documented. It is done by skilled artisans who don’t see the point of writing down stuff for efficiency experts.
In the naughties IT was consolidated to achieve scale. It was then optimised using methodologies like LEAN and outsourcing to manage cost, but IT never simplified. Complexity is always, at least, preserved it seems.
LEAN, consolidation, outsourcing. We ended up with many gutted-out, off-shore script shops. A disaster waiting when something undocumented or unexpected occurs. Previously salaried employees returned as contractors. IT in some ways became more fragile.
In fact, Taleb argues, and I agree, excessive size, efficiency/optimisation and complexity generally makes things more fragile. Efficiency leads you to put all you eggs in one basket. To lean on single vendors (pun intended) and have big hidden risks. Times have changed. Efficiency is becoming dangerous.
That’s not to say we gold-plate IT. I like Agile. Even though it not always implemented well, Agile recognizes IT as “The Cat” it is. It works with small teams, learns and improves (fails fast) quickly.
I suspect a good number of IT professionals will continue to balance efficiency/fragility with robustness when in fact the we should start looking at anti-fragility. We should look at more ways for IT to improve itself under stress.
We want failure to make IT better and stronger. Isn’t this the big takeaway from ITIL problem management? Isn’t this what Chaos Monkey does for Netflix? A non-functional process destroying things at random to improve the Netflix ecosystem.
What other examples can you think of where IT improves itself under stress? And do MBAs with the latest efficiency fad represent a risk to IT systems?